
Identity Resolution
Introduction
Identity Resolution is a crucial component of customer communication. Establishing and maintaining a well-defined identity resolution strategy is essential, but it can be overwhelming to get started. Several challenges may arise, such as limited and outdated customer data, data silos, technical difficulties, in-flexibility, consistency, compliance, and maintenance.
Lytics offers a solution that powers brands' identity resolution strategies by aggregating data from disparate sources, defining a standardized customer schema, unifying disparate sources, surfacing individual consumer profiles, enabling better understanding, segmentation, and activation across channel tools, ensuring control, visibility, flexibility, security, privacy, and compliance, and maximizing match rates and accuracy across activation channels.
The goal is to construct complex consumer profiles and maintain accurate and compliant user profiles as your brand evolves. Defining the relationship between consumer identifiers is a necessary first step in surfacing unified user profiles that enable your brand to create the best consumer engagements while meeting evolving compliance requirements. To achieve this, we've broken our approach into three components:

Our Approach
Define: Relationships Between Identifiers

Profile definition is the first step in surfacing unified user profiles that enable your brand to create the best consumer engagements while meeting evolving compliance requirements.
To build a strong identity resolution strategy, three key questions must be answered:
- How important is accuracy?
- How do you define and manage the strength of each identifier to ensure profiles are materialized properly?
- How can the materialized profiles be analyzed and delivered to other tools?
Construct: Complex Profiles
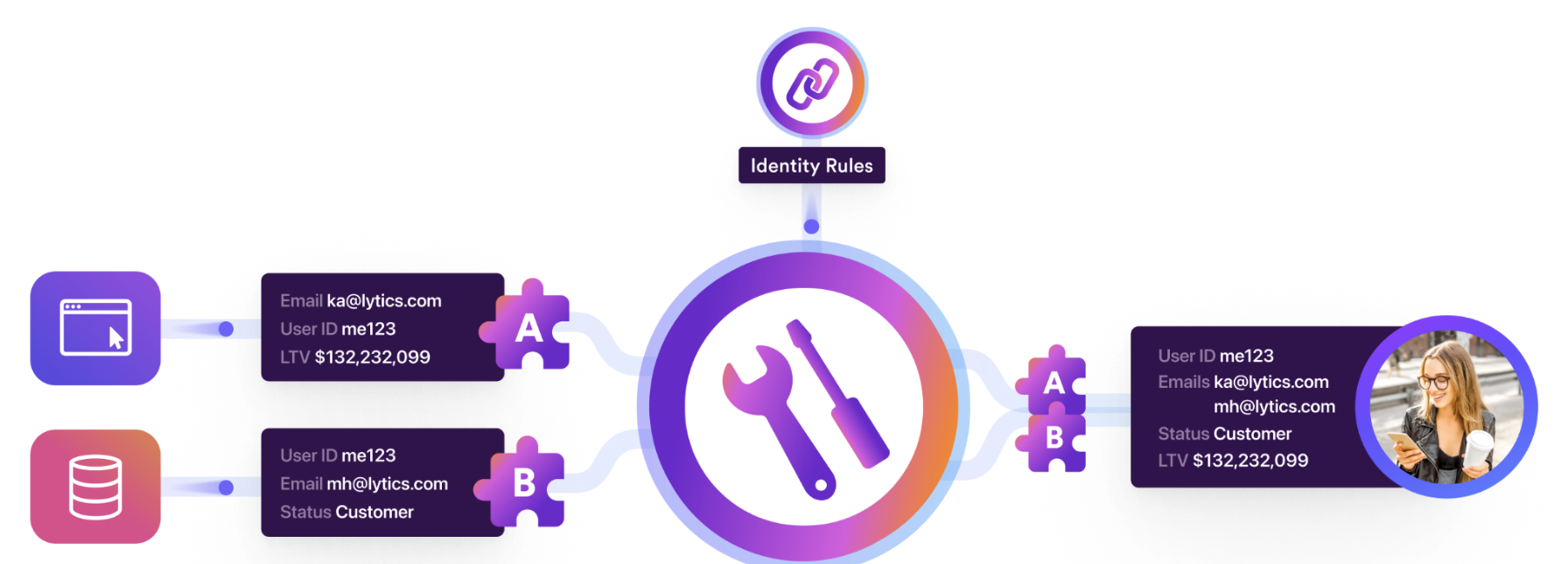
Data is messy. Lytics' Profile Materialization provides a necessary cleansing & polishing layer atop the defined resolution strategy. This ensures what is surfaced is accurate and accessible and enables your team to accelerate impact.
Answering the following two key questions guarantee profiles represent the ideal marketable entity:
- What attributes should be surfaced on profiles for segmentation, and does the data need to be normalized at all?
- What rules should be used to maintain profile integrity?
Maintain: Accurate & Compliant Profiles

Over time profiles will bloat, attributes will become stale, and use cases become more complex. If unmanaged, a quality identity strategy will begin breaking down the moment it is implemented.
Lytics prevents your identity strategy from breakdown through a set of powerful tools focused on ensuring the following profile health-related questions have concrete answers:
- How can you validate the health of your ID resolution strategy over time?
- What is the process for managing consent?
- How long is a profile relevant if it no longer has a means of being updated?
- What is the life expectancy of expirable IDs, such as browser cookies?
Advanced Concepts
The Lytics Identity Graph
Behind each Lytics profile is an identity graph. This graph represents connections between pieces of data observed across multiple sources or even within a single source.
To create (or update) profiles from a data stream, the stream must contain one or more identity keys that identify distinct users with which to associate the data. When data is observed for a given identity key, it stores the relevant profile metadata in an object called an identity fragment. When there's evidence on a data stream that two keys or fragments should be connected
When evidence on a data stream shows that two keys or fragments identify the same real-world entity, those fragments become connected in the same identity graph. Some identity graphs are significant and represent complex relationships in the data. In contrast, other identity graphs are small and describe a small interaction, like an anonymous cookie from a single-visit, incognito browser.

Graph Mechanics
As you learned from the identity resolution overview, a profile comprises one or more identity fragments. Many profiles start as singletons – new data is observed on a data stream. That event's identifier keys create any necessary identity fragments and store the event's associated data on that fragment.
However, we're not satisfied with several singletons – our objective is to stitch data sources together by linking the appropriate underlying fragments. Stitching occurs when we observe two identifiers in a single event. A common stitching event is a newsletter signup, where the email address from the newsletter form is linked to the cookie from their web activity and creates a link between activity from the browser on the device and any activity associated with the email address, which could eventually encompass purchases, support tickets, CRM data, etc.
In graph terms, stitching creates an edge between two nodes representing two identity fragments. If we wanted to retrieve a profile associated with an email address, we would retrieve all of the fragments with edges or connections to other fragments. From there, we'd want to find all of the connections to those other fragments, and so on, until there are no more connections to follow. Following one fragment to another is called traversal. The full set of fragments that are found to have connections to the initial fragment are called neighbors.
In Lytics, default graph limits cap the number of traversals allowed for an individual profile at 50 and cap the number of neighbors allowed at 50. Changing these values can create different sets of user profiles over the same data set and should not be adjusted lightly. To change these values for your data, please contact Lytics support.
Identity Keys
As we traverse identity graphs, we'll quickly find that identity fragments and their corresponding identity keys are not all created equal. An identifier's strength must contribute proportionally to its influence on identity resolution.
For example, you have email addresses and cookies as identity keys. Generally, a user identified with an email address can have multiple cookie values (from different devices, browsers, periods, etc.). Imagine hosting a promotional, in-person event and having multiple tablets collecting participants' email addresses. Depending on how those email addresses are collected (most likely through an online form), you'll likely have one cookie associated with many email addresses.

Field Types
Field types for Identity Keys can be either a string or a string set. String sets are a common field type for cookies since one profile is expected to have many cookie values over time. Email addresses are not so cut-and-dry. Some organizations will constrain profiles to have one email address, while others will allow profiles to have multiple (personal, work, etc.). In our example of email collection via physical tablet, if the email address is a single-valued string type, we won't end up with an over-merged hairball.
Using an identity key that allows for a set of values is usually a good idea to have a sensical capacity cap on the field type. A set of cookies, for example, might have a capacity limit of 50 values. On the other hand, a set of emails might have a capacity limit of 5 values.
Identity Key Rankings
The ranking of your identity keys should reflect their reliability and their relative importance in the strategy. In the event of a conflict in stitching and merging, higher-ranked identity keys will win. Typically, most Lytics users configure email identifiers to be ranked higher than cookie identifiers.
Imagine a scenario where email A is connected to cookies X and Y, while email B is connected to cookie Z. If new data is observed that connects email B with cookie Y, we have a conflict, meaning that a resulting stitching between the two fragments would yield a profile with two different email fragments and violates our merge rules.
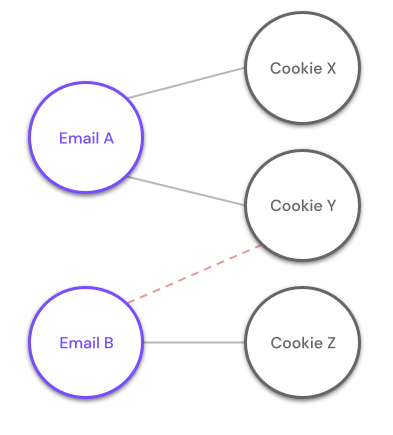
The ranks of identity keys would dictate that, for the new event, the email address it contains is of a higher priority than the cookie value that it contains and would consequently update the profile for Email A and not the profile for Email B.
Graph Compaction
We mentioned that a critical tenet of bulletproof identity resolution is that profile complexity remains stable over time. That is, we need a way to ensure that a relatively greedy algorithm doesn't result in profiles becoming more fragile and susceptible to conflicts.
In Lytics, that is accomplished via graph compaction, a process by which data from multiple fragments is combined into a single fragment. Doing so allows well-established relationships in the graph to be solidified while making room for new relationships within the profile. It functions more as a type of profile housekeeping to keep profile fragments tidy.
Compaction in identity graphs can take on a few forms.
Rank-based Compaction
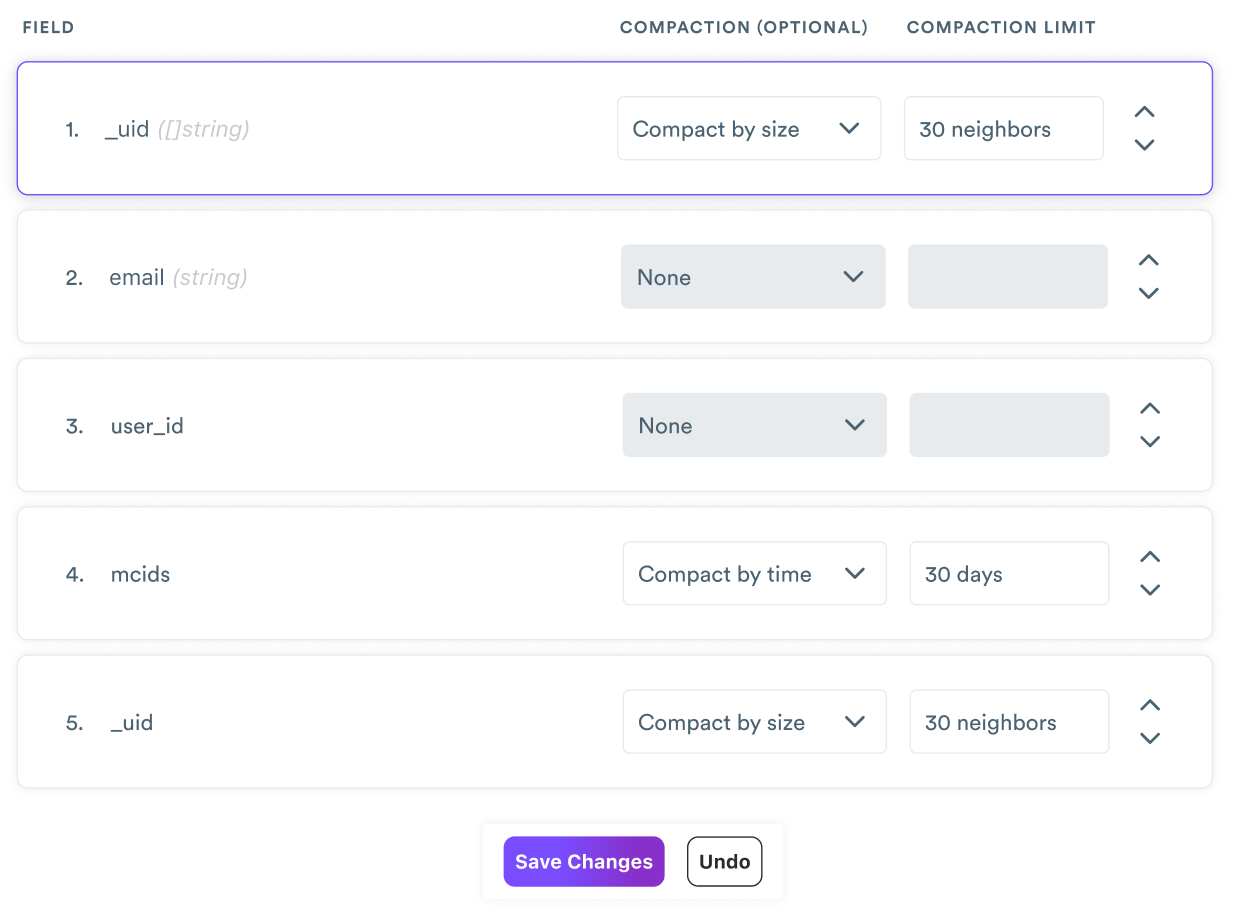
Let's go back to our example with Email A and Email B. The point of identity resolution within a customer data platform is to enable long and rich relationships with customers. The longer that Email A and Email B represent profiles in the platform, the more cookies with which they'll eventually become connected. Each identity key's ranking allows an identity graph to compact by size or time.
- Size compaction: Identity key sets can be compacted after they reach a configurable size. If size compaction is enabled to compact a set after 30 values, then the data from the oldest 30 fragments would be combined into a single fragment and would be further compacted with new data as new values are observed.
- Time compaction: These sets would be compacted after a configurable time threshold. If time compaction is enabled to compact a set after 14 days, then the data from fragments older than 14 days would be compacted into a single fragment.
Updated 9 months ago