

Job Processing
Overview
Lytics Job runtime and APIs control the mechanics of how data flows in and out of Lytics. Lytics jobs can be generally broken down into a few important categories:
- Direction: Does this job route data to Lytics, or from Lytics?
- Subject: Does this job target entities (commonly known as profiles)? Or does it target raw events?
- Schedule: What starts this workflow? Is it based on real-time triggers? Or does it run on a batching schedule?
- Termination: Is this a one-time job, or is it expected to run again? If so, on what frequency?
Knowing which type of job you're dealing with can help guide expectations for behavior and troubleshooting.
Auths
Some jobs, like specific Webhook flows, don't require explicit credentials to access external systems. However, most jobs require some form of authorization to retrieve data from or send data to external systems. In Lytics, these credentials are generically referred to as Authorizations.
Authorizations can be managed from the Auth API, or directly from the Lytics interface. All authorizations are either configuration-based or OAuth-based.
- Configuration: The authorization is based on credentials provided to Lytics. These usually take the form of API keys/secrets and usernames/passwords.
- OAuth: The authorization is given access delegation from an OAuth flow.
Commonly, authorizations will change – some systems require periodic password changes, tokens get revoked, users who complete OAuth flows leave an organization, etc. Consequently, a job that is running successfully with authorization today may fail tomorrow if the authorization is no longer valid. If you know in advance that credentials will update or change, it is recommended that you create a new authorization and update the job to use the new one.
To stay alerted on the health status of a job, you can set up alerts as described in the Monitoring section below.
Configuring and Submitting Jobs
Jobs can be managed from the Jobs API, or directly from the Lytics interface.
Each job has custom configuration options that tell the job when to run, what type of data to pull, which lists to pull data from in external systems, how to send the data to downstream sources, etc. Each job's API endpoint will validate the presence of any required parameters, or other conditions that must be satisfied for the job to run correctly. In the event of a validation error in the job configuration, the API will return a 400 error with a message indicating what is misconfigured.
If the configuration for the job request is valid, the job will be immediately submitted to Lytics internal job running system.
Job State Machine
Jobs running on Lytics' internal job running system may be in any of the following states:
- Runnable: The job is currently running.
- Completed: The job has run successfully and is not scheduled to re-run.
- Paused: The job has been manually paused, and will remain so until it is unpaused or terminated.
- Sleeping: The job is in between runs and is scheduled to run again at a later point in time.
- Failed: The job has exceeded its retry limit and will not attempt to run again.
- Terminated: The job has been manually terminated and will not attempt to run again.
Jobs will usually first enter into a Runnable state. If the job is fed input from real-time triggers, it will stay running unless it encounters any errors. If the job runs on a batched interval, it will usually switch between Runnable and Sleeping.
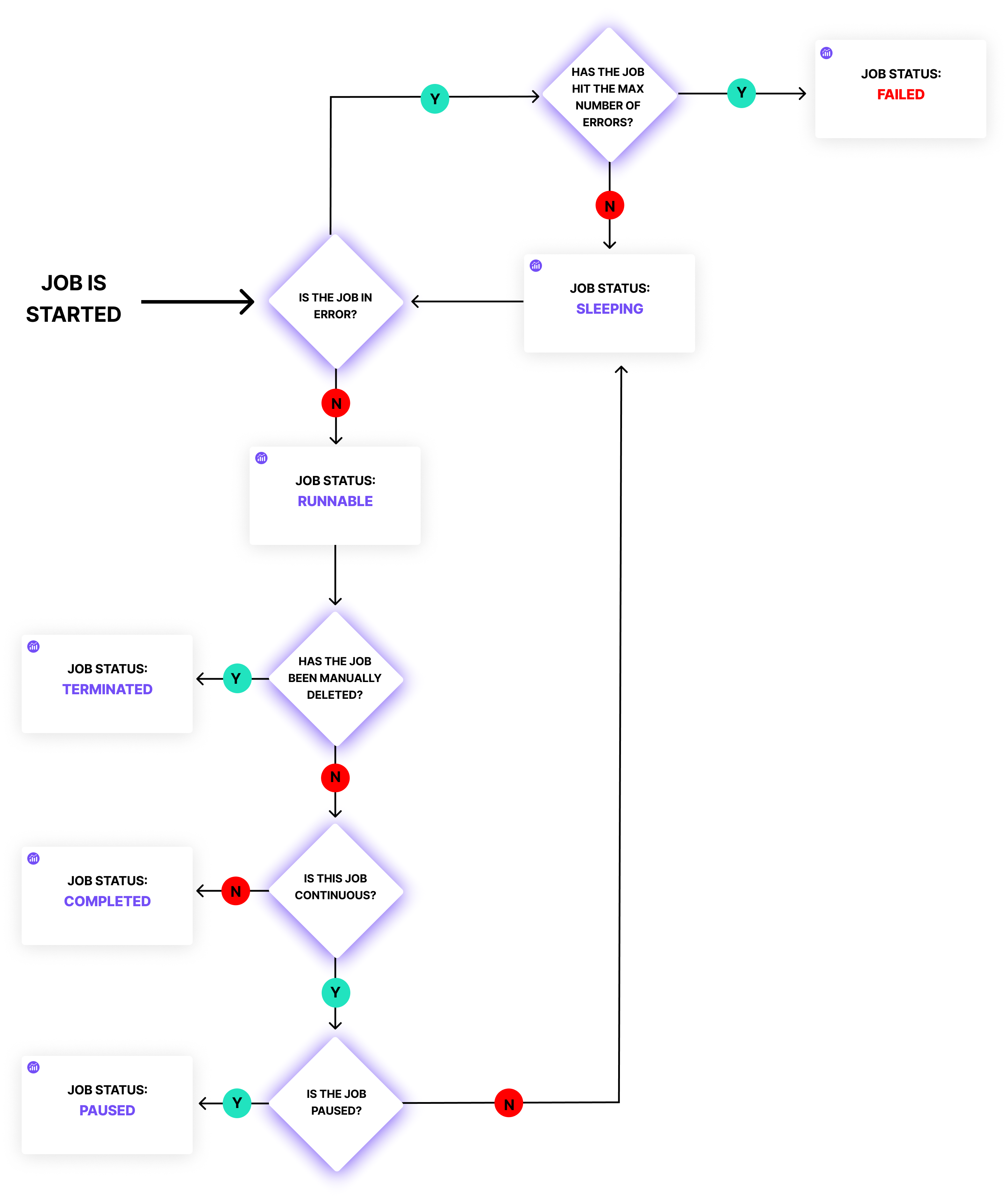
While most transitions happen automatically in the system (Runnable → Completed, for example), some are triggered manually, namely:
| From | To | API Route |
| Sleeping, Runnable | Paused | /v2/job/{job}/{id}/pause |
| Paused | Runnable | /v2/job/{job}/{id}/resume |
| Failed | Runnable | /v2/job/{job}/{id}/bounce |
| Any | Terminated | /v2/job/{job}/{id}/kill |
Errors
There are a variety of reasons a job will enter a Failed state, including:
- Authorization issues: This is the most common reason for job failures. Some authorizations can become invalid if the external system requires periodic password changes and the authorization isn't updated, if tokens get revoked, or if users who complete OAuth flows leave an organization and the token no longer has access to the resources it is requesting.
- External failures: Sometimes external systems can produce intermittent failures, like HTTP 503 errors if the system is temporarily unavailable. Because of their intermittency, it's less likely that one of these errors will result in a job ending in a Failed state.
- Internal Lytics failures: While rare, sometimes the availability of internal Lytics resources can cause a job to fail. Because of the high availability of Lytics systems (>99.9%), it's unlikely that a job will be in a Failed state from Lytics internals.
When an error occurs, the job will enter a Sleeping state, and retry a minute later. If an error occurs on the second attempted run, the job will sleep double the amount of time as the previous run. If errors still occur after two hours, the job will enter a Failed state.
Any failed work can be manually restarted, through the Job API or through the Lytics interface. If, for example, a job is in a failed state because of an authorization issue, you can create a new authorization for the job and restart it.
Contributing
Many jobs are maintained by Lytics, and even more workflows can be enabled by using our generic tooling for Webhook and SFTP-based integration flows.
Some jobs are open-sourced and run on the Lytics Opus framework for running jobs. Check out our Opus Template on GitHub to get started creating your own jobs.
Updated 2 months ago