

Classification
The Classification page offers insight into how your content is being scraped, indexed, and categorized by the Lytics Content Affinity Engine. You can access this page under the Content menu, and it includes two main sections: the Classification Dashboard and Content Classification.
Classification Dashboard
The Classification Dashboard displays the Classification Activity, Content Flow, and the Content Dashboard components. Learn more about each component below.
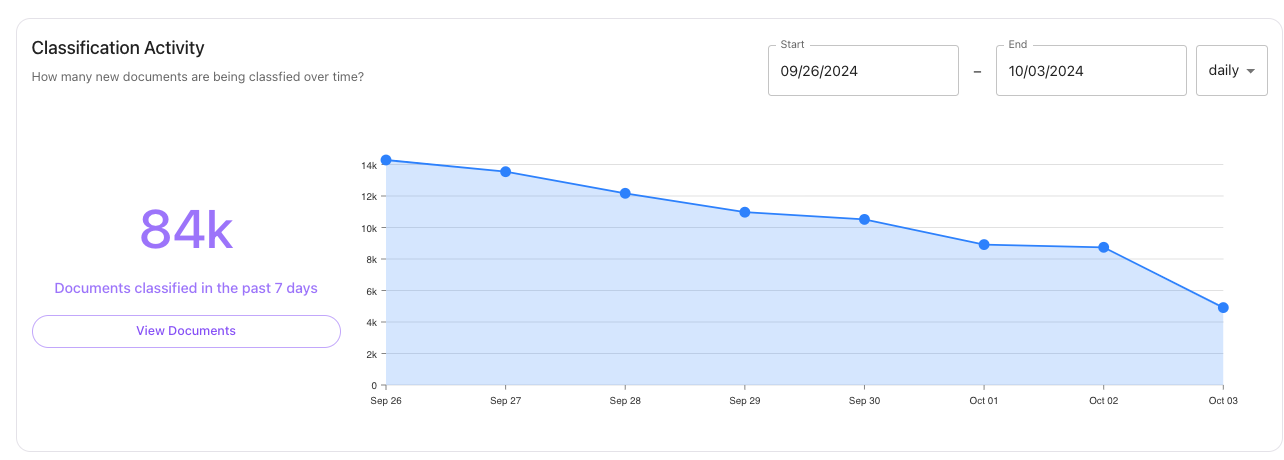
Classification Activity
The Classification Activity section shows how many documents the Lytics Content Engine is classifying. By default, Lytics will classify up to 20,000 documents per month, which includes new documents as well as periodic reclassification of existing ones. This section helps you track whether you’ve reached your monthly quota and ensure the Content Engine is functioning as expected.
The Lytics Content Engine runs multiple workflows in the background, including the content classification workflow, which updates hourly. As long as you haven’t exceeded your monthly quota, you can expect hourly updates to the classification activity.
If your account has hit the content classification quota in previous weeks, you may notice a lack of data in the chart for the current week. Adjust the date range to see when content was last classified.
Content Flow Visualization
(The Content Flow chart visualizes how your documents are ingested, processed, and enriched with Topics by the Lytics Content Engine. It also highlights any errors or problematic URLs such as URLs that are blocked by robots.txt directives, Account Settings, or URLs that encounter non-200 status codes.
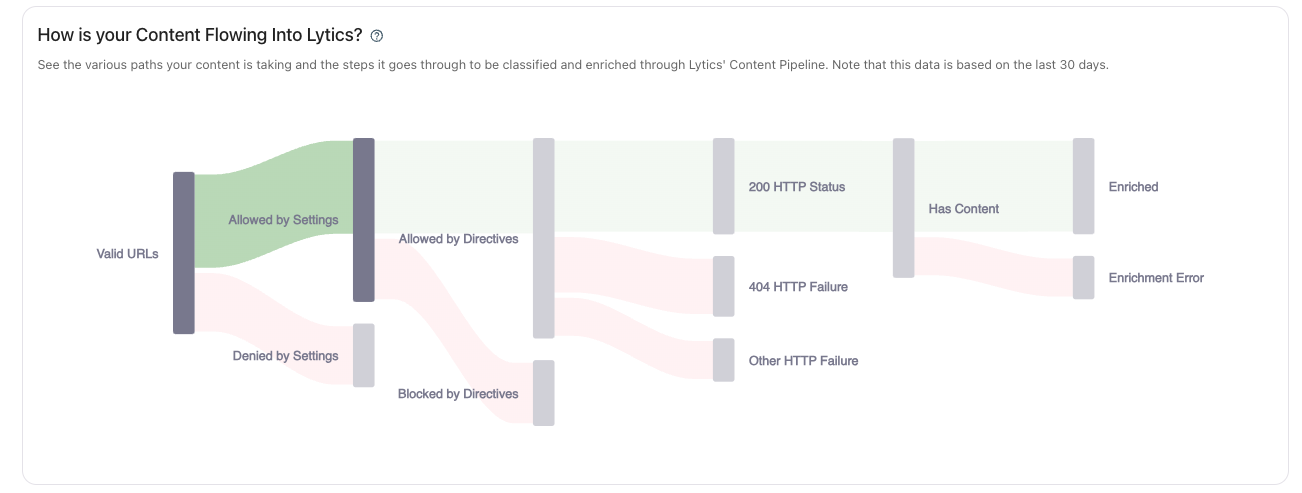
Each state in the Flow diagram is described in detail below:
- Valid URLs: URLs that are properly formatted and can be fetched by Lytics. This step checks for invalid characters, symbols, and protocols.
- Allowed By Settings: URLs permitted by the Domain Allowlist, Path Allowlist, and other account settings that control if the URL can be scraped.
- Denied By Settings: URLs not included in the Domain Allowlist setting.
- Path Blocklist: URLs blocked from being scraped based on the Path Blocklist setting.
- Allowed By Directives: URLs that are allowed to be scraped according to robots.txt directives.
- Blocked By Directives: URLs that are blocked or disallowed according to robots.txt directives.
- 200 HTTP Status: URLs that return a 200 status code, indicating they were successfully fetched.
- 404 HTTP Status: URLs that return a 404 status code, indicating the URL was not found
- Other HTTP Status: URLs that return a status code that is not 200, 404, or 401. This means the URL was not successfully fetched.
- Has Content: URLs that have content to be scraped. This means the URL was successfully fetched and contains content.
- Enriched: Content that has been successfully enriched with metadata and Topics
- Enrichment Error: Content that encountered an error during enrichment, meaning it was not successfully enriched and may lack metadata or Topics.
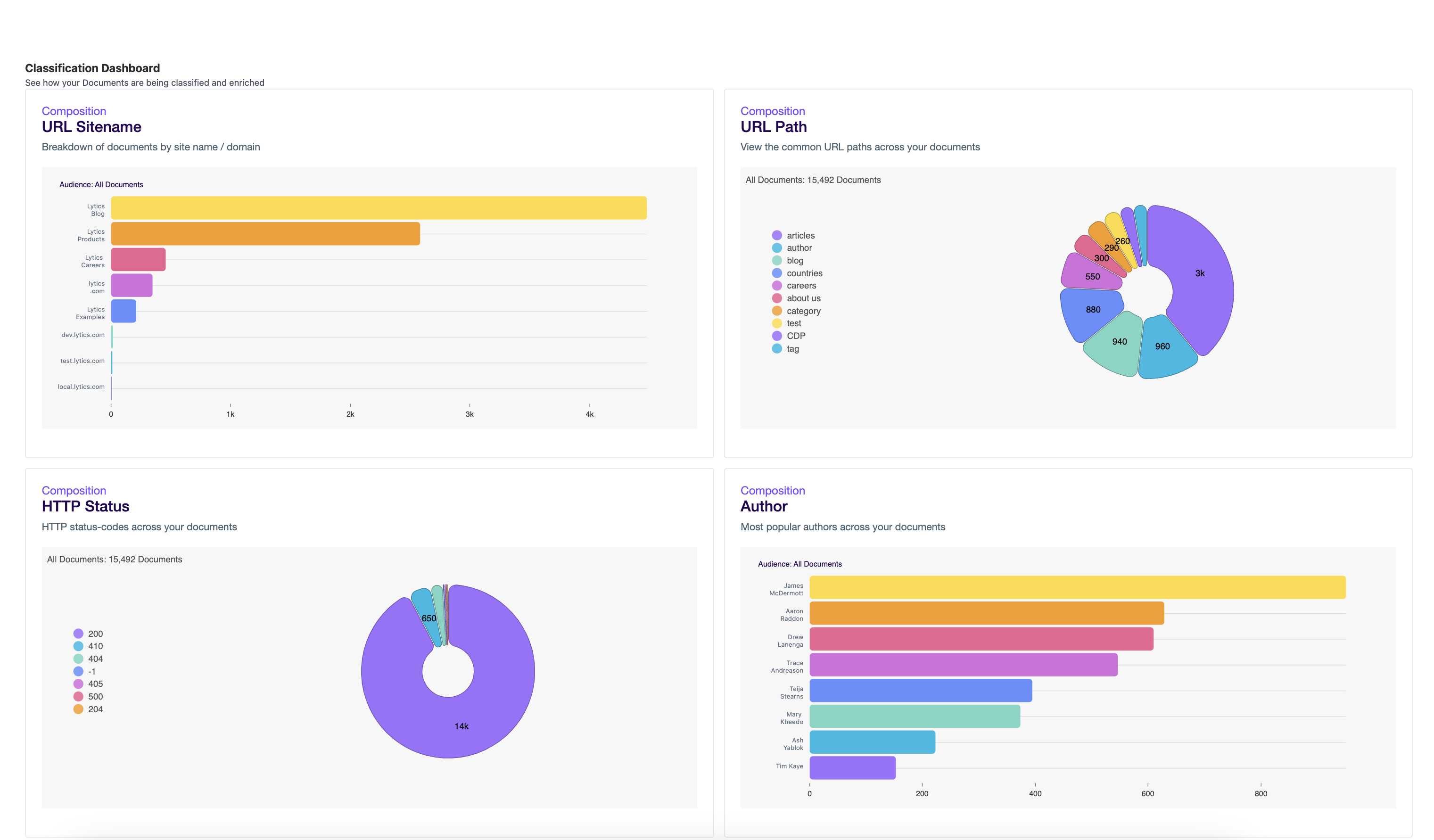
Content Dashboard
The Content Dashboard displays various attributes of your Content, including site name, author, URL path, and Topic information. The Classification Dashboard is intended to provide a high-level understanding of your Content and can be used as a starting point for your Content-oriented use cases.
Manual Content Classification
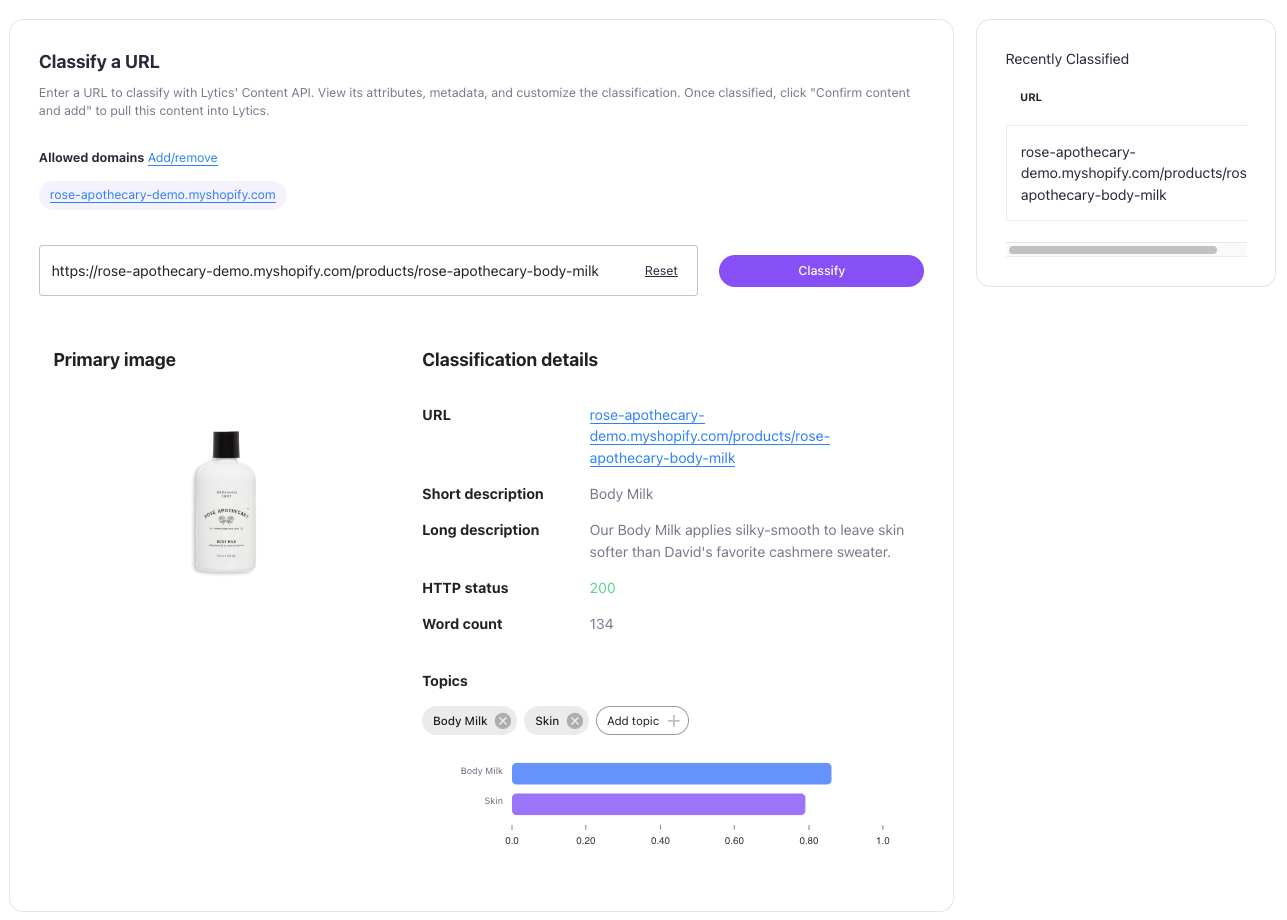
The Manual Content Classification module allows you to manually add a URL to Lytics or preview how a specific document will be classified. This feature is useful for troubleshooting any setup issues on your page before it’s added to the Lytics content corpus.
To use it, simply enter the URL of the document you want to preview and click Classify. You’ll be able to see the extracted Topics as well as any metadata that Lytics scrapes from the document.
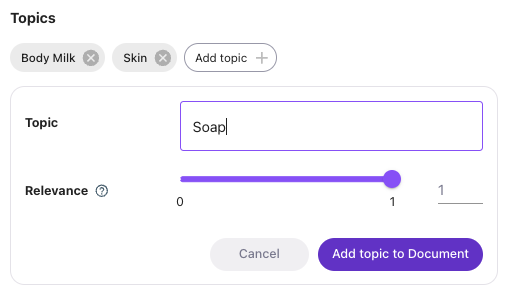
Adding and Removing TopicsWhen previewing a document, you can manually Add or Remove topics from the Classification. To add a Topic, click the
Add Topicbutton, select the desired Relevance score (between 0 and 1) and then clickAdd topic to Document.To remove a Topic, simply click the X next to the Topic tile.
Once you're satisfied with the results of the classification, click Complete Classification to add the Documentto the content corpus. The document and its associated Topics will then be available for use in personalization efforts, such as recommendations or content affinity.
URL Normalization
As Lytics ingests web-based content, it attempts to resolve duplicate URLs and create links between documents, much like a search engine would. As such, Lytics does things like respect robots.txt directives, resolve canonical URLs when present, etc.
Lytics attempts to sanitize URLs as much as possible before ingesting them into the Content Affinity Engine. Sanitization includes removing all URL parameters and cleaning URL syntax. This happens via an LQL function called urlmain.
Updated 10 months ago