

Documents
What is a Document?
Lytics considers every piece of content as a "document", and calls the collection of every document a "corpus". Lytics automatically processes every web page for an account's site, where each web page is a "document". In the Lytics app, documents are surfaced in association with topics and in content recommendations.
Keep in mind that the Lytics Content Affinity Engine isn't limited to your website content. All sorts of content can be sent to Lytics, including product catalogs to power Product Recommendations.
Finding Documents
To search for a document in Lytics, go to the Search page under the Content menu. Enter a URL or search term, then click Search to find the relevant documents.
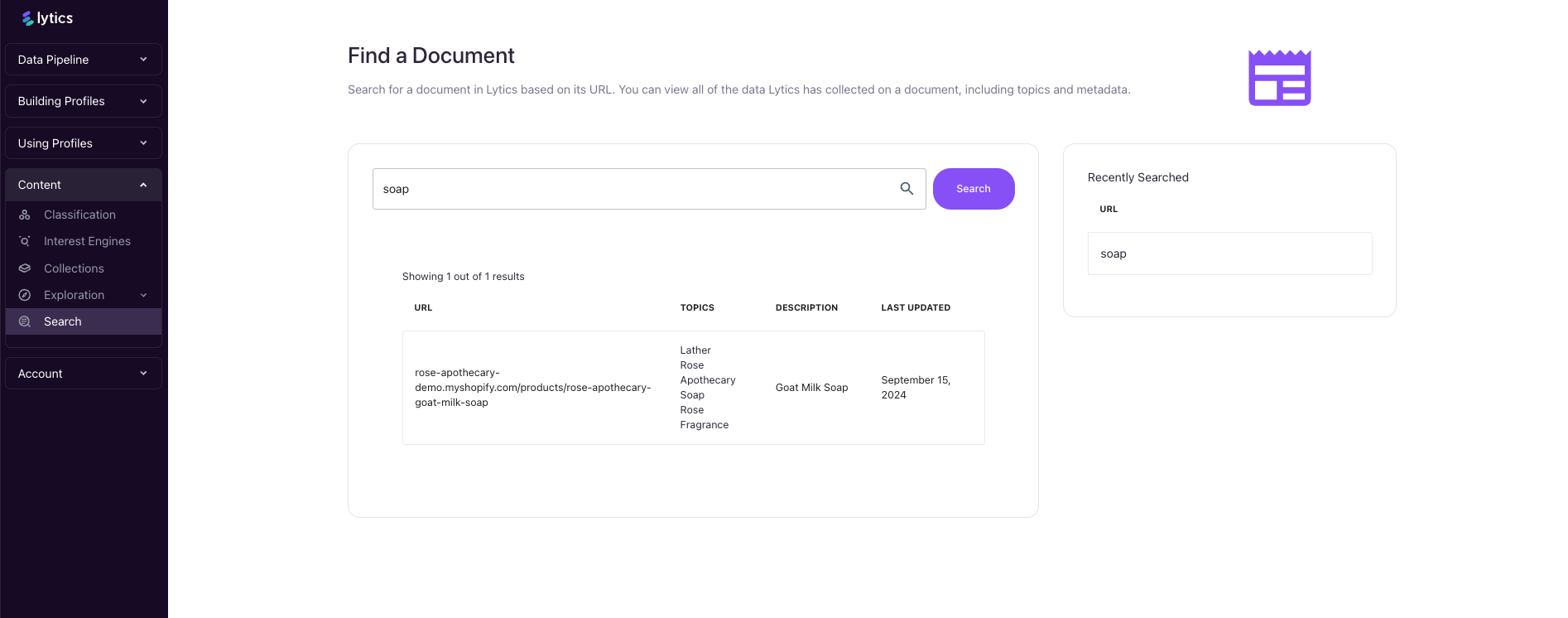
Clicking on a row will lead you to the Document Summary page, which contains more details about the Document.
Document Summary
Details Tab
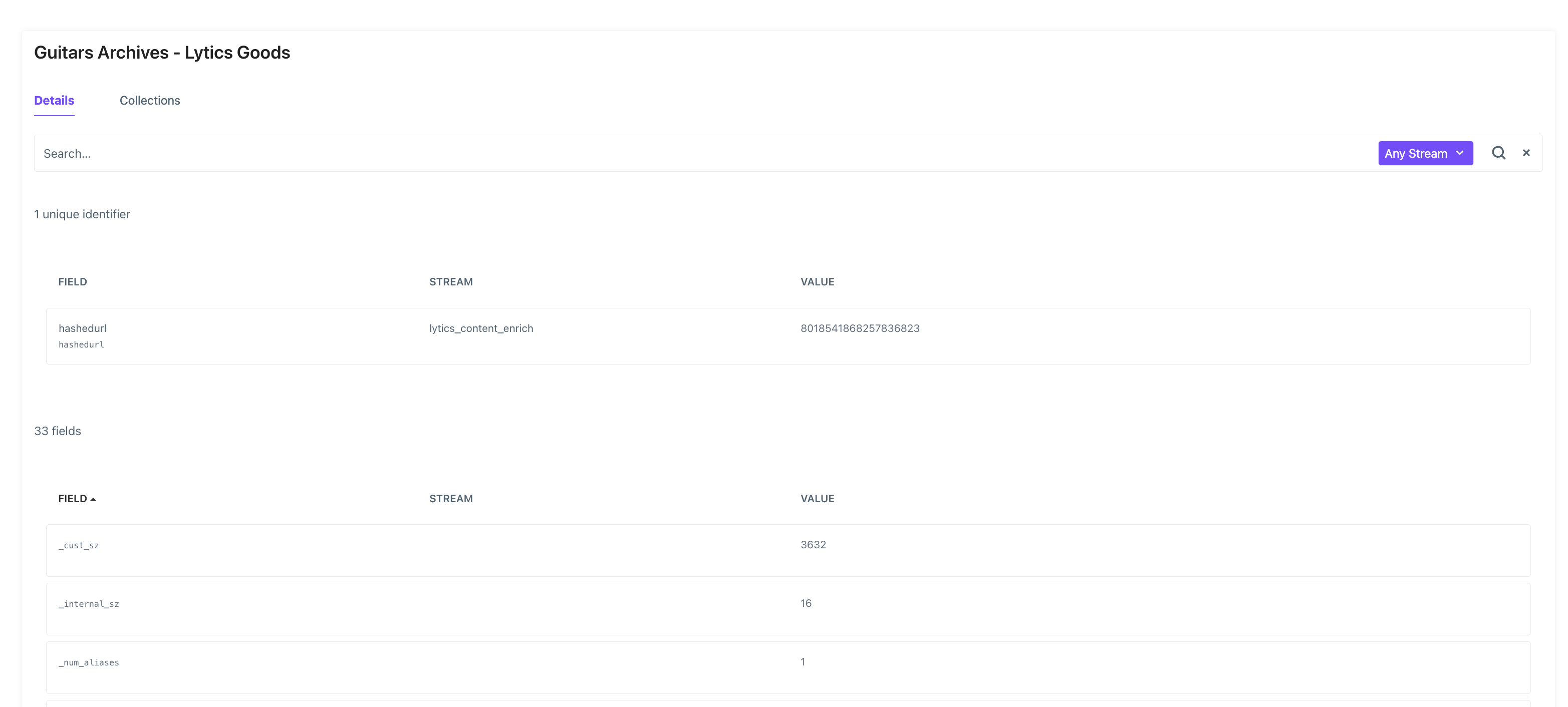
On an individual document page you are able to see all the fields associated to that particular document within the Details tab.
Collections Tab
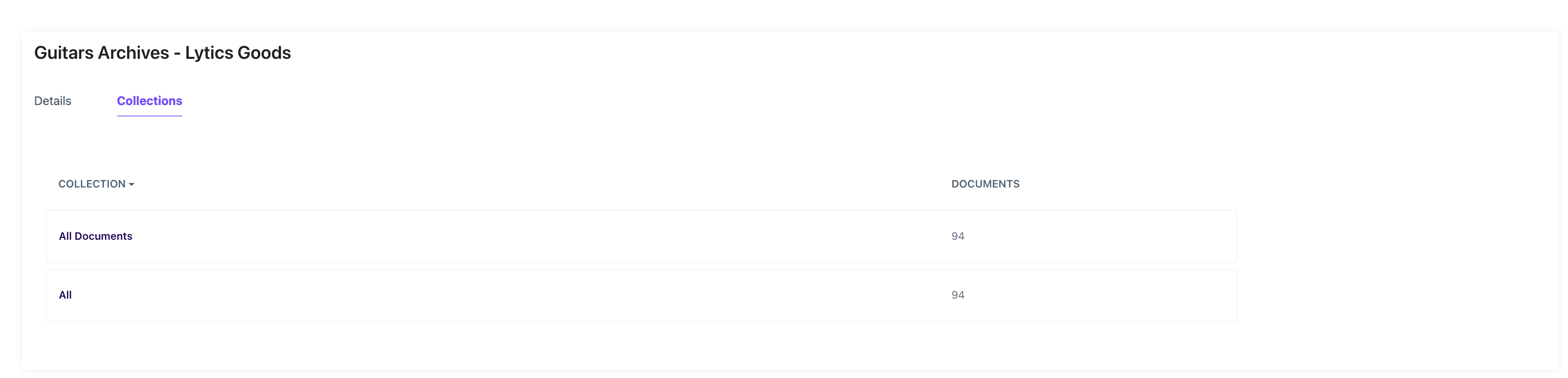
To see if this document is used in any Content Collections, you can view the Collections tab.
If you make adjustments to any of your documents, such as updating a blog post or refreshing a product landing page, you can request Lytics to manually re-classify the document. This will ensure the Lytics content corpus has the most up-to-date information to serve in any of your content or product recommendations.
Adding New Documents
By default, Lytics observes new URLs in all data streams to identify content with which the user is registering activity. New URLs are enriched as they're observed in incoming data — that is, Lytics can crawl a domain, but proactively indexing a domain and looking for new content is not part of the Content Affinity Engine's workflow.
To add new documents to your corpus:
You can send new documents directly to our Content Corpus API. The Corpus API respects three parameters:
url: An optional URL for a new document. While most documents are identified with a URL, documents aren't constrained to be web accessible. In the event that you have custom content that is not web accessible, you'll need to supply the content via thetextparameter.text: An optional string of content for a document. This is only really necessary in the event that the new document is not web accessible.topics: An optional list of topics relevant to the document. When Lytics tries to enrich the new document, the resulting topics will be appended to this list. In the event that you only want your own custom topics added to a document, you'll need to contact your account representative at Lytics Support to remove all external enrichment settings.
You can also use the manual classification module to preview the enrichment of a URL and then add it to the content corpus.
Customizing Document Properties
Adding custom properties to a document allows you to create advanced content collections based on those custom properties. Imagine creating recommendations from a pool of custom categories, promoting pages with custom seasonality components for particular holidays, adding a custom SKU hierarchy to better reflect your product catalog within Lytics, etc.
The Lytics crawler can detect custom document properties from custom meta tags — any meta tag with a name property prefixed with lytics: will be ingested and appended onto a document. For example, a meta tag with the name lytics:sku will update the sku field on that document.
<meta name="lytics:sku" content="SKU123" />
<meta name="lytics:category" content="electronics" />
<meta name="lytics:genre" content="action" />
<meta name="lytics:subgenre" content="spy fiction" />When Lytics scrapes new documents, it will append those properties on the newly generated content entity within Lytics. When adding a field that isn't currently represented within the content schema, the content query will need to be updated with the new property.
Updated 10 months ago