

Creating Lookalike Audiences
Once your Lookalike Model is built and users are scored (ensure the Model Training Only option is unchecked, or press Activate in the top left of the Model Summary page), you can begin creating Lookalike Audiences with varying decision thresholds or percentiles based on model predictions.
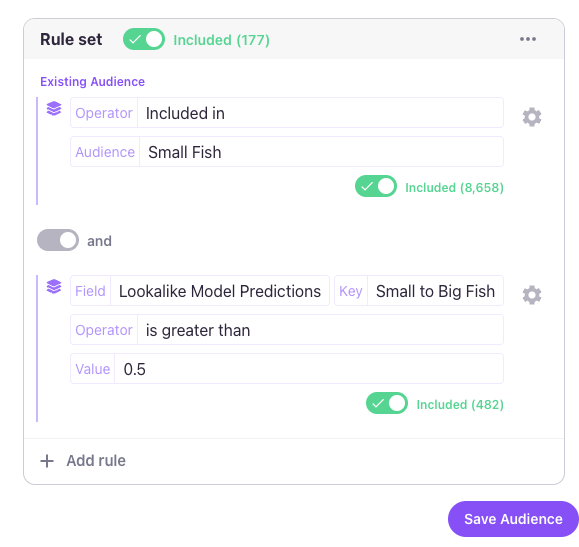
To create a new Audience, click the Create New Lookalike Audience button on the modal page. This opens a dialog where you can choose between the Quick Editor and the Advanced Editor. When setting up the new Audience, you will use either the Lookalike Model Predictions field or the Lookalike Model Percentiles field (explained further below).
Model predictions are expressed as probabilities on a 0-1 scale, with values closer to 0 indicating a low likelihood of resembling users in the target audience, and values closer to 1 signifying a higher likelihood.
You can adjust the threshold as you like or add additional rules before saving the audience. See Improving Lookalike Models for tips on adjusting the Decision Threshold. Any audiences built using the audience prediction score for your model will display in the model usage module.
Using Lookalike Model Percentiles
Another option to build a Predictive Audience is by using the Lookalike Model Percentiles field. Similar to the Lookalike Model Predictions field, the Lookalike Models are keys for the Lookalike Model Percentiles field.
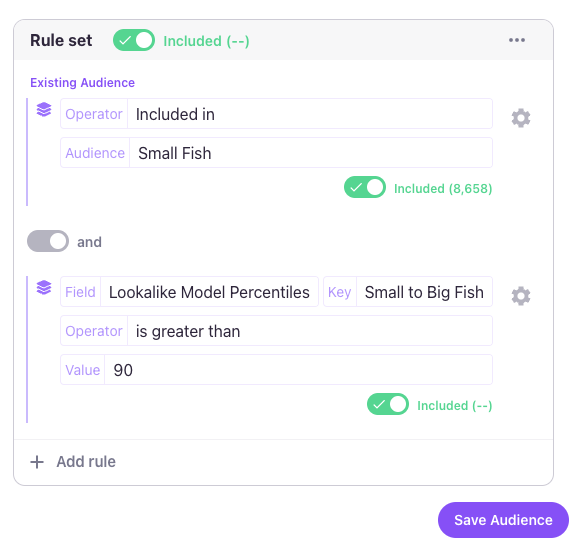
The percentile for a model represents the value at which a percentage of the predictions fall below. For example, the 80th percentile represents the prediction score at which 80% of all other scores fall below, or more simply put; the top 20% of users. Percentiles help account for the shape of a model's prediction distribution, as it can sometimes be hard to determine who the best users are based solely on the prediction scores, if the distribution is skewed is any direction.
Updated 10 months ago